SEOに欠かせない構造化データマークアップとは?基礎から詳しく解説!
Webサイトを運営しているみなさんは、Webサイトを構造化データマークアップをしていますか。構造化データマークアップをするとSEO対策に効果が出てくるのはもちろん、リッチスニペットやAmpにも対応することが可能になってきます。今回は、構造化データマークアップとはなにかという基礎的な話から設定方法までご紹介します。


ハイブリッド型受講を可能に。医療団体に特化した研修管理システム。
https://manaable.com/
manaable(マナブル)は、利用ユーザー数25万人を突破した医療団体向け研修管理システムです。会員や研修から決済・受講・アンケートまで、研修管理に必要な機能を網羅。あらゆる業務の一元管理を可能にしたシステムだからこそ、お客様に合わせた革新的で最適な研修体制をご提供します。
目次
構造化マークアップとは
構造化データマークアップとは、コンピューター(検索エンジン)が効率的にWebサイトの情報を収集して解釈できるように、Webサイトのテキスト情報をマークアップして意味を持たせる手法のことです。
ちなみに、Webサイトの構造を一定の規則に従い正しく意味付けして、コンピューターが自律的に情報の収集を行えるようにする考え方のことを「セマンティックWeb」と呼びます。
例えば
- Webサイトの名前は〇〇〇です。
- Webサイトの概要は〇〇〇です。
- Webサイトの設立者(会社)は〇〇〇です。
- 記事の公開日時は〇〇〇です。
と検索エンジンにWebサイトの情報をひとつひとつ伝えるイメージです。 こういった説明をHTMLファイルに記述することが、構造化マークアップです。
ボキャブラリーとシンタックス
構造化データマークアップを行う際に使用するのがボキャブラリーとシンタックスです。
ボキャブラリーとは
ボキャブラリーとは、構造化データマークアップで使用する単語を定義した規格です。例えば、名前を表すときは「name」、記事の出版者を表すときは「publisher」という単語が対応していることを、このボキャブラリーで確認できます。
代表的なボキャブラリーは「schema.org」や「deta vocabulary」がありますが、Googleが使用を推奨しているのは「schema.org」です。
ボキャブラリー:schema.orgとは
schema.orgとは、Google、Yahoo!、Microsoftなどによって策定されていた、検索エンジンが情報を理解しやすい構造化データを作成し、管理するプロジェクト、ボキャブラリーやその表記方法のことを指します。
サイトによってschema.orgとは何かという説明の仕方はまちまちですが、ボキャブラリーであるということだけ理解できれば問題ありません。
シンタックスとは
シンタックスは、ボキャブラリーにある単語の使い方だと思ってください。構造化データマークアップはHTMLに記述すると書きましたが、その記述の仕方がシンタックスにあたります。
代表的なシンタックスは「JSON-LD」や「Microdata」「RDFa」がありますが、Googleが推奨しているのは「JSON-LD」です。
シンタックス:JSON-LDとは
JSON-LDとは、構造化データを記述する際に使用するシンタックスです。schema.orgの策定に関わっていたGoogleが利用を推奨し、さらにW3Cの勧告も受けています。
JSON-LDは、scriptタグを用いてHTMLのどの部分にも構造化データを記述できるという特徴があり、構造化データにしたい部分に直接記述する必要がある他のシンタックスに比べて、記述内容を整理しやすいというメリットがあります。

構造化データマークアップ
ここからは、構造化データマークアップの方法について説明します。 ボキャブラリーにはschema.org、シンタックスにJSON-LDを使用します。
まず先に、構造化データマークアップの全体をお見せします。
- <script type="application/ld+json">
- {
- "@context" : "http://schema.org",
- "@type" : “Article",
- "mainEntityOfPage": {
- "@type": "WebPage"
- "@id": "記事のURLを書く"
- },
- "headline" : "記事見出し分",
- "image" : {
- "@type" : "ImageObject",
- "url" : "画像パス",
- "height" : 画像の高さ,
- "width" : 画像の横幅
- },
- "publisher" : {
- "@type" : "Organization",
- "name" : "企業名",
- "logo" : {
- "@type" : "ImageObject",
- "url" : "ロゴ画像のパス",
- "height" : ロゴ画像の高さ,
- "width" : ロゴ画像の横幅
- }
- },
- "author" : {
- "@type" : "Person",
- "name" : "記事の著者"
- },
- "datePublished" : "初回公開日時"
- "description": "記事の説明を書く"
- }
- </script>
まずは記述の構造の説明をします。
先ほども説明した通り、JSON-LDはscriptタグを用いて記述します。
script typeの中には「application/id+json」と記述しましょう。
scriptタグ内側の{}の中に構造化データを記述します。
ルールは3つです。
1. 単語は「”」で囲い「:」で分け、意味の区切りで「,」を使う
単語は「"(ダブルクォーテーションマーク)」の中に書き、「"」で囲った2つの単語の間には「:(コロン)」が入ります。
また、CSSと同じように、意味の区切りで「,(カンマ)」を使いましょう。
2. 最初に使用するボキャブラリーを宣言する
検索エンジンにどの種類のライブラリを使って記述するかを宣言しましょう。
今回は”schema.org”です。
3. @typeで要素を定義する
@typeは、直前の単語の種類を定義する記述です。
- "image" : {
- "@type" : "ImageObject",
- "url" : "画像パス",
- "height" : 画像の高さ,
- "width" : 画像の横幅
- },
例えば上記の記述は、@typeでimageに対して「imageOcject」という定義をした後に、画像パス、画像の高さ、画像の横幅を定義しています。
- "author" : {
- "@type" : "Person",
- "name" : "記事の著者"
- },
この部分の記述で、@typeでPersonと定義した後にはnameで名前を定義しているように、@typeで定義した種類によって、それ以降に定義できる要素が決まっています。
ちなみに、4行目の@typeだけ他の@typeと記述の仕方が違うように見えますが、これはWebページそのものを対象に定義している記述です。
以上の3つのルールさえ理解すれば、あとはボキャブラリーを確認しながらコードを記述することができます。
構造化データマークアップのコードの意味
下記の表にschema.orgでよく使用されるコードをまとめました。
| コード名 | 意味 |
| headline | 記事のタイトル |
| mainEntityOfPage | 正規ページのURL |
| @id | urlを記述する |
| image | メイン画像 |
| ImageObject | 画像について説明する際に使う |
| url | url |
| height | 高さ |
| width | 幅 |
| publisher | Webページの設立者 |
| Organization | 組織 会社 |
| name | 名前 |
| logo | ロゴ |
| author | 著者 |
| Person | 人 |
| datePublished | 記事の初回公開日時 |
| description | 記事の説明 |
基本的に単語の意味がそのままコードの意味となっています。datePublishedなど、2単語以上続く場合は、2単語目以降の頭文字を大文字にしてくっつけるというプログラミングのルールがありますので、気を付けましょう。
ここで紹介した単語はschema.orgにある中のごく一部です。schema.orgでよりそのWebサイトにあった単語を見つけることができれば、より詳細な構造化データマークアップをすることが可能です。
【コラム】AMP対応やリッチスニペットにも使用される構造化データ
AMPとはAccelerated Mobile Pagesの略称で、高速でモバイル端末専用のWebページを表示する手法のことです。AMPは、GoogleとTwitterで共同開発されていて、ニュースページ・記事ページ・ブログ記事ページ・レストランページなど多くの形態に対応しています。
通常、Webページにアクセスする際、URLにアクセスすると、同時にHTMLを読み込みはじめます。そのため、Webページをすぐに表示することはできません。 AMPでは、Webページ表示の高速化を実現するために、GoogleもしくはTwitter側がWebページのHTMLのデータを保存 (キャッシュ) し、HTMLを読み込む時間を削減します。
そして、WebページをAMP対応させるためにも、今回のテーマである構造化データが使われています。
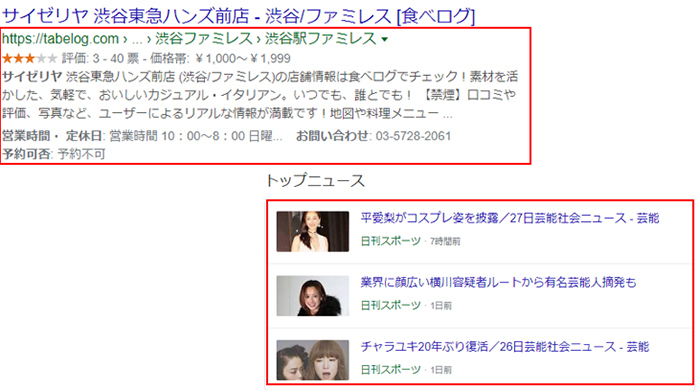
他にも、構造化データマークアップをすることでGoogleでそのWebページがリッチスニペット(リッチリザルト)として表示される可能性があります。リッチスニペットとは、検索結果のタイトルの下に表示されるページの要約、抜粋をしたテキストやサムネイル画像や、検索結果の上に表示されるニュース記事枠、動画枠のことです。
構造化データマークアップを理解することで、様々なメリットが得られますね。
まとめ
構造化データマークアップについてご理解いただけたでしょうか。今回はschema.org、JSON-LDを使用して説明しましたが、これら以外のボキャブラリーやシンタックスもあるので、自社のWebページの構造にとって扱いやすいものを選択しましょう。
Web担当になったけれど自分の知識に自信がない、自社のWebページをもっと改善したい、けれども、うちにはそんな時間も人材もないというお悩みはございませんか?
WebMediaを運営するITRAではお客様に真摯に向かい、ご要望に沿ったWebサイト制作やリニューアルを行ってきました。お気軽にお問い合わせください。
この記事の著者

ITRA株式会社
官公庁や大手企業を中心とした大規模なWebサイトを総合的にプロデュースするWeb制作会社。デザインからシステム、サーバーまでWebサイトに関わるお客様の悩みを解決します。

